scikit-learnで学ぶ機械学習に必要なライブラリ4選


機械学習について、学ぼうと思っている人
scikit-learnってどんな機械学習ライブラリなんだろう
scikit-learn だけで機械学習ができるのかな
この記事では、scikit-learnで機械学習を学ぶために必要なライブラリを紹介しています。
ゼロからしっかり機械学習を学びたい方は「Pythonではじめる機械学習」がオススメです。
難しい数式をできるだけ使用せずに、初学者にもわかりやすく解説されています。
機械学習で重要な scikit-learn とはどんなライブラリ?
① 機械学習分野において、もっとも重要とされているライブラリ
② オープンソースプロジェクトで再配布自由で無料で使用できる
③ 開発と改良が活発に行われており、広いユーザコミュニティが存在する
④ 個々のアルゴリズムに対して、詳細なドキュメントが用意されている
> http://scikit-learn.org/stable/documentation
> http://scikit-learn.org/stable/user_guide.html (ユーザーガイド)
⑤ 他の科学技術向けPythonツールを群を組み合わせて使う事ができる。

なお、scikit-learnは「Numpy」と「SciPy」ライブラリに依存したライブラリとなっている為
セットでインストールする必要があります。
scikit-learn を使用するうえで必要なライブラリ
機械学習においては、多次元配列や線形代数、フーリエ変換、疑似乱数生成など、科学技術計算をする必要がありますが、これらを一つずつ全てプログラミングする必要はありません。
なぜならば、Pythonにはこれらの処理を行ってくれるライブラリが多く用意されているからです。
そのなかでも、必須とも呼ばれる重要なPythonライブラリをご紹介します。
もし、これから機械学習を始めようと思っている方は、これからご紹介するものはライブラリをインストールしておく事をオススメします。
Numpy

Nmpyは、科学技術計算をする際の基本的なツールの1つ
機械学習に必要な、「多次元配列、線形代数、フーリエ変換、疑似乱数生成」などの数学関数が用意されている。
コード
import numpy as np
x = np.array([[1,2,3],[4,5,6]])
print(x)
結果
[[1 2 3]
[4 5 6]]
SciPy

高度な科学技術計算を行うための関数を集めたもの
scikit-learnは、Scipyの関数群を利用し実装されている。
機械学習において、Scipyの「scipy.sparse」は、疎行列(成分がほとんど0の行列)を表現する為の重要な要素となっている。
コード
import numpy as np
from scipy import sparse
eye = np.eye(4)
sparse_matrix = sparse.csr_matrix(eye)
print(sparse_matrix,"\n")
data = np.ones(4)
row_indices = np.arange(4)
col_indices = np.arange(4)
eye_coo = sparse.coo_matrix((data, (row_indices, col_indices)))
print(eye_coo)
結果
(0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0
(0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0
matplotlib
もっとも広く使われている、グラフ描画ライブラリ
折れ線グラフ、ヒストグラム、散布図などさまざまな可視化方法がサポートされている。
データや解析結果をさまざまな視点から可視化することで、重要な洞察を得られる。
こと、教師あり学習においてはデータが命とも言えるため、可視化のライブラリは必須となっている。
コード
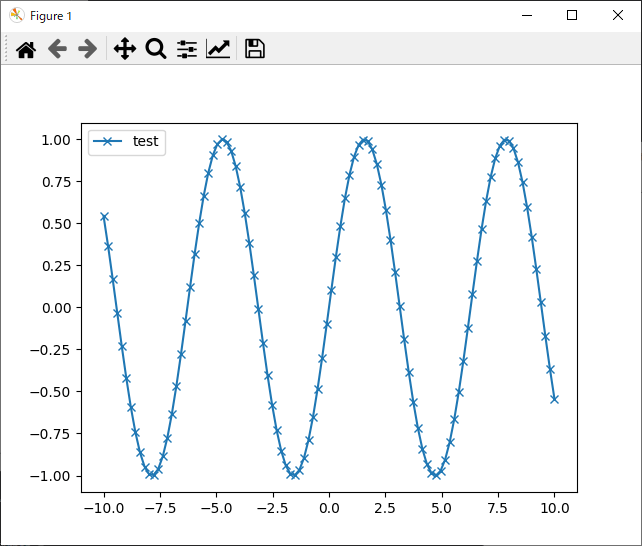
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
y = np.sin(x)
plt.plot(x, y, marker="x", label="test")
plt.legend()
plt.show()
結果
pandas

データを変換したり解析したりするためのライブラリ
データを、エクセルの様な表形式で可視化したり、外部からデータを取り込みNumPyの配列形式に変換などを行う際に用いる。
コード
import pandas as pd
data = {'Name':["John", "Anna", "Peter", "Linda"],
'Location':["New York", "Paris", "Berlin", "London"],
'Age':[24, 13, 53, 33]
}
data_pandas = pd.DataFrame(data)
print(data_pandas[data_pandas.Age > 30])結果
Name Location Age
2 Peter Berlin 53
3 Linda London 33
機械学習の基本はデータ分析にある
「 機械学習の基本はデータ分析にある」と言うだけあって、必要なライブラリも「データ分析」や「データの操作・可視化」に関するものばかりだったと思います。
基本的には今回ご紹介したライブラリを使用して、機械学習を進めていく事になると思います。詳しく知りたい方は 「Pythonではじめる機械学習」で学習する事をおすすめ致します。
というわけで、記事は以上となります。
ここまで見ていただき、ありがとうございました。
ではまた😀
